
How Bidirectional RNNs learn from both past and future context
Running an RNN architecture in two directions to help boost performance.

Hello fellow machine learners,
Last week, we talked about Long Short-Term Memory as a solution to the RNN vanishing gradient problem. Take a look if you missed out:

We have talked at length about the utility of RNNs for sequential data like text. In order for machine learning models to interpret text correctly, they must be precise in their interpretation of words. To that end, homonyms can provide a common pitfall. A homonym is a word that can have multiple meanings for the same spelling. The word ‘orange’ is a good example; it can refer to either the colour or the fruit. Take a look at the following sentence:
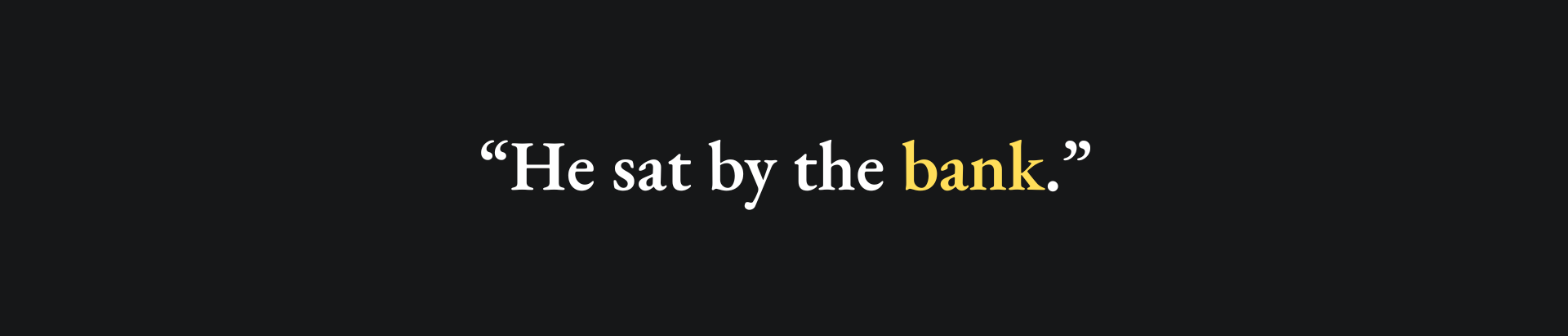
The question is: does the word ‘bank’ refer to a bank for money, or a river bank? By revealing the rest of the sentence, we understand which is correct:

If this ambiguity persists when training a model on text-related tasks, it can have negative effects on the model’s performance. A common use case for text-based machine learning is Named Entity Recognition (NER). This is an area of Natural Language Processing dedicated to the detection of people, places, etc. and is used in pieces of software like search engines and chatbots. NER cannot be executed accurately by a machine if it gets stumped by homonyms. In the bank example shown earlier, you would probably get annoyed if a search engine started showing results about river banks when you were looking to apply for a job at a corporate bank.
How can we deal with this? Assuming the title hasn’t given the game away too much…
…let’s get unpacking to find out!
Bidirectionality
A vanilla RNN takes previous words and uses them as information. We have seen variants of my standard RNN diagram a few times now:
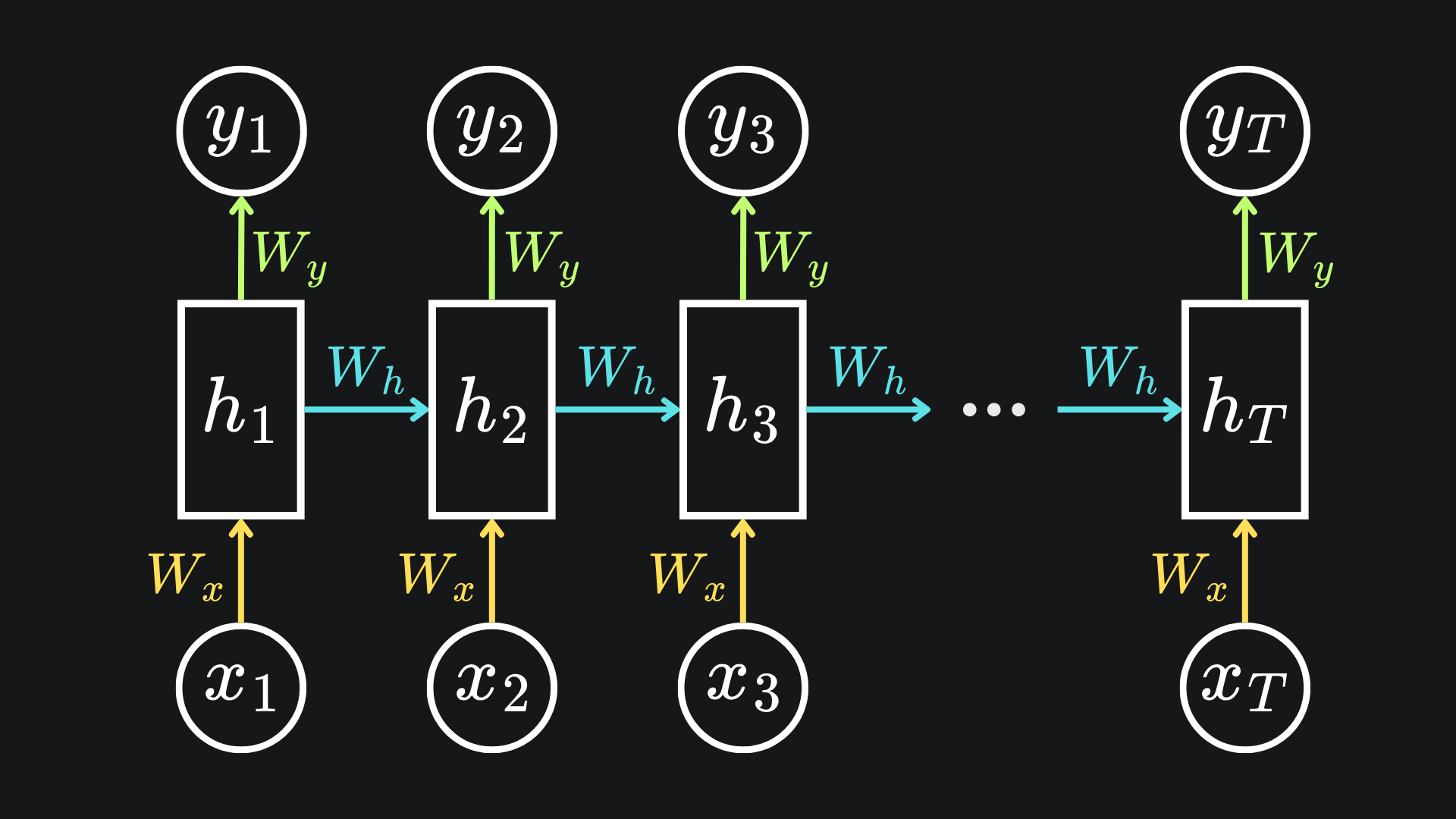
If this looks like gibberish, check out my first RNN article here:

Now, what if we were to set up the RNN so that it takes the words in backwards? Something like this:
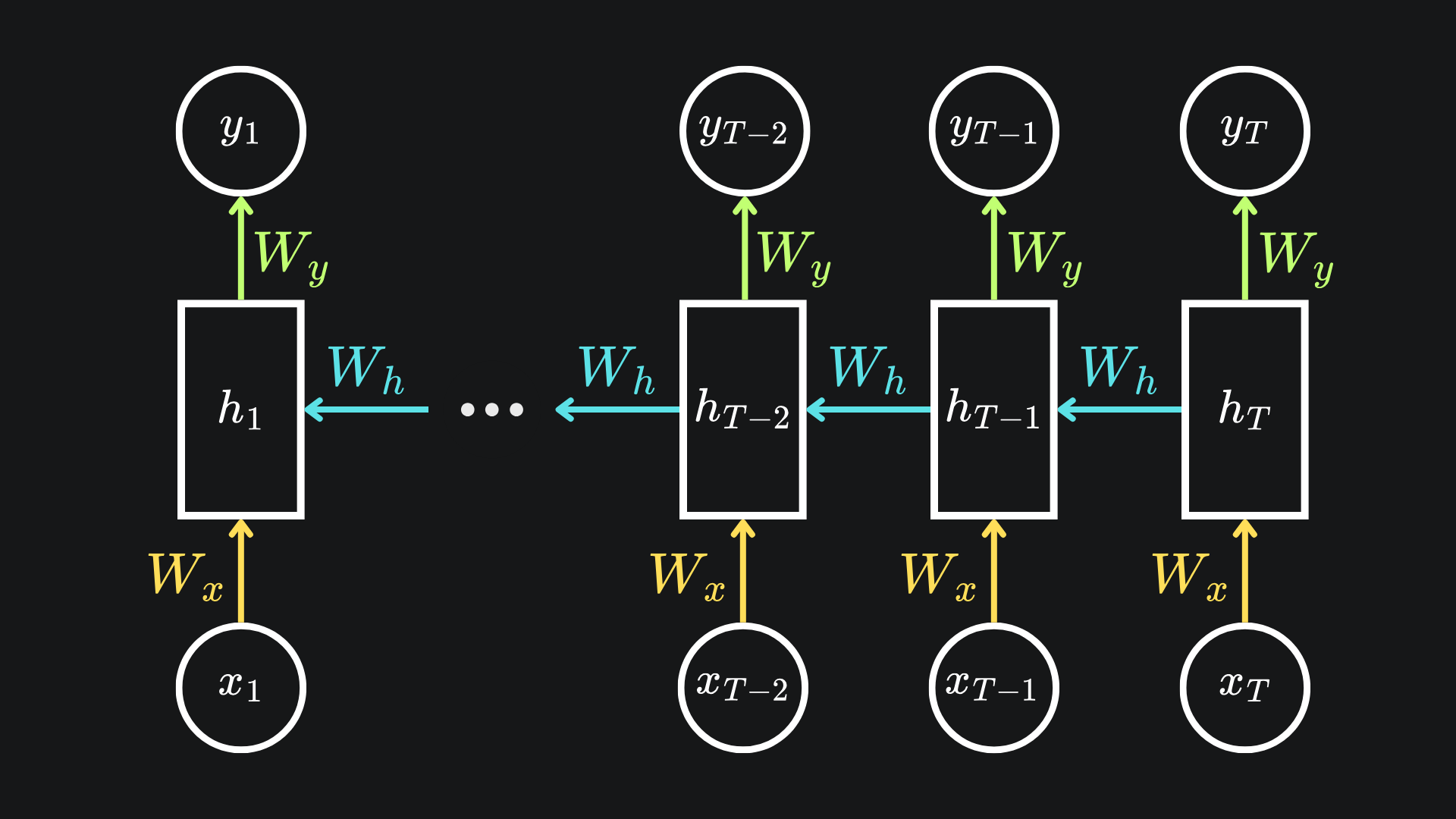
This means that we begin by updating the (usually final) hidden state hT with the final word xT. From there, we evaluate hT-1 by using the penultimate word xT-1 and hT. Then, we use xT-2 and hT-1 to inform hT-2, repeating the process until we arrive at the initial hidden state h1.
In general, each hidden state is affected by the next hidden state in the sequence, rather than the previous. This process allows the RNN to use future words to inform the hidden state.
However, it does not suffice to simply run the RNN backwards like this. Why? Have a look at the following sentence:

Running an RNN backward, the model may assume that the football game is cancelled unconditionally. While it might be able to infer that the statement is conditional by the time it gets to the start of the sentence, it may still struggle to pick up on this, especially because it sees the word “if” as the last word.
Thus, what we really want to do is run the forward and backward versions at the same time and combine the hidden states at each timestep. This would allow for the combination of both past and future words to influence network’s overall understanding.
Diagrammatically, this is what I mean:
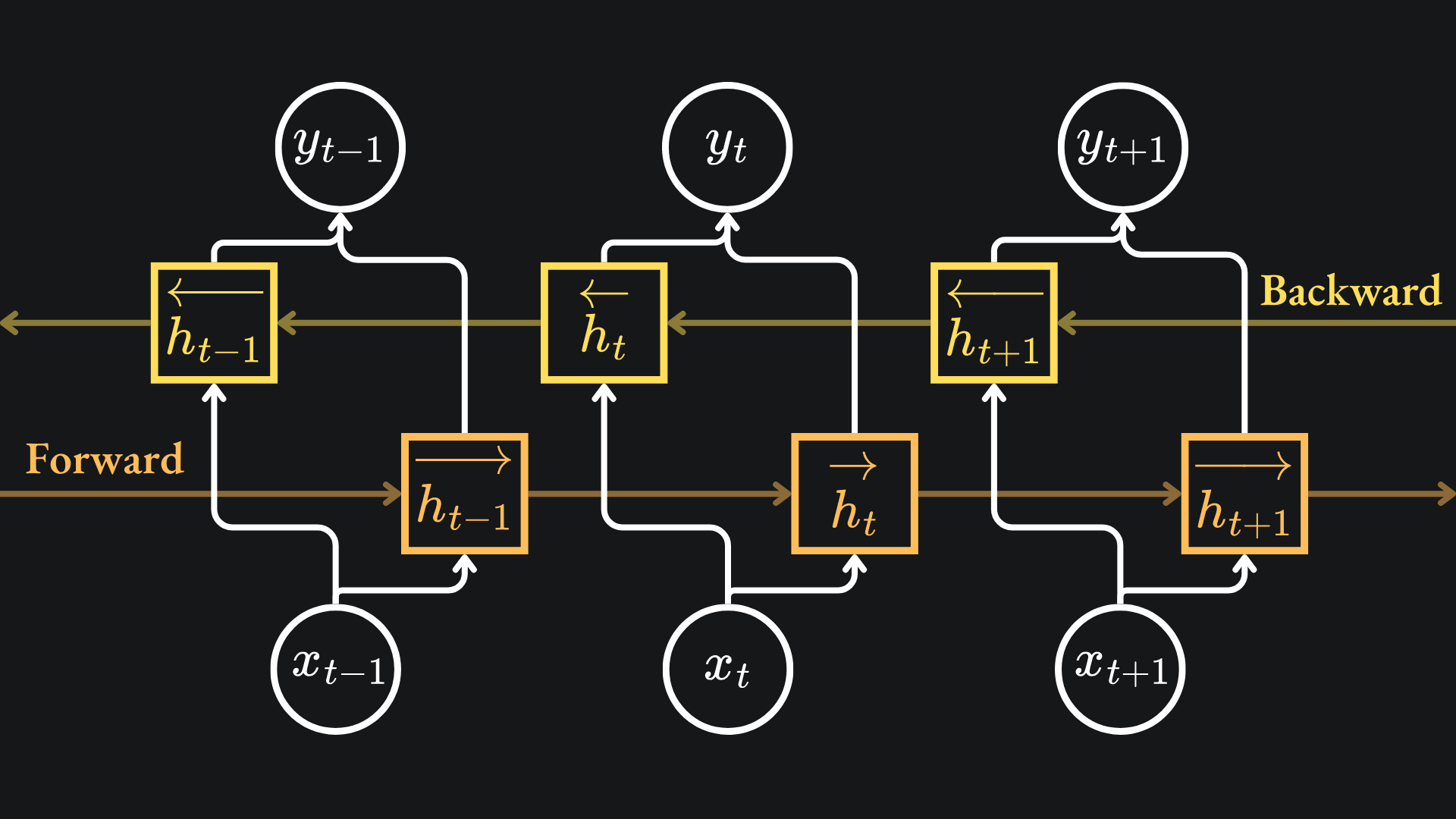
To actually combine the values from the forward and backward methods for the output, we vertically stack the hidden states:
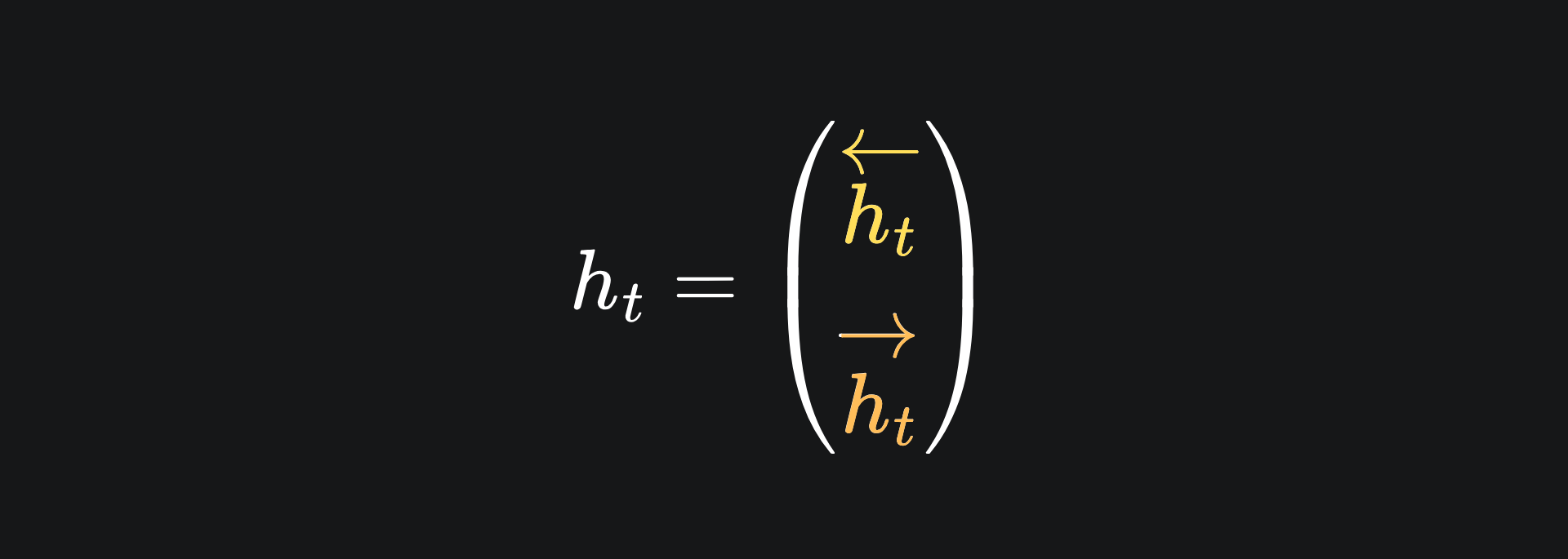
This can then be multiplied by a weight matrix (followed by the application of an activation function if desired) to give us the network output at step t, yt, just like in the vanilla RNN case.
This two-way RNN mechanism is called (you guessed it) a bidirectional RNN.
Why does this work?
This is a question that has lingered on my mind as I’ve been writing this RNN series. I think last week’s LSTM article exemplifies the question quite well. While I explained the importance of the Sigmoid and tanh activation functions in the LSTM gates, I still wondered to myself why that combination of functions and gates just happens to emulate the desired long short-term memory effect. Similarly, with bidirectional RNNs, if we just combine the forward and backward hidden state values, then we can (apparently) rest east knowing that the network’s weight updates will pick up on the patterns in our training data.
Neural network architectures can perform incredibly well at learning tasks, but this is often at the expense of us not being to interpret what their weights’ values correspond to. If we were to train an RNN and then look at the values in the hidden state, as well as the weights, I would not be able to point at a section and say something like “oh well, this bit corresponds to fact that the network learned…”. That is to say, all neural networks are black box models. We can’t really interpret what’s going on inside of them, regardless of how strong their performance metrics are.
Rather, we put our faith in the maths behind backpropagation and trust that, under the right circumstances, our models will produce reasonable results.
Another issue with neural networks is knowing what architectures to even use. Take the CNN architecture from my Pokémon classification article. I simply followed the combination of convolution and pooling layers specified in a pre-print. But the researchers behind that pre-print likely spent a long time experimenting with different combinations of layers, kernel dimensions/quantities, etc. to come up with a CNN that produced good results.
The development of the LSTM unit likely involved experimentation to an extent. Hochreiter, Schmidhuber, etc. probably spent a lot of time bashing together different combinations of activation functions and gates to get something meaningful in the end. However, I imagine that they had an intuition for what behaviour they wanted to simulate, with a mathetmatical grasp of the bare minimum functions they’d need to achieve it- such breakthroughs in science do not happen by chance.
In any case, here is the link to the original bidirectional RNN paper, so you hear from the creators of the architecture!
Limitations
Besides the above remarks on interpretability, a clear limitation of bidirectional RNNs is the fact that we require access to future data during the training process. This can be either inconvenient or straight up impossible, for instance when deploying of an RNN system that must interpret data as it’s being received in real time.
Another big problem is that we have to train two separate RNNs to make up a single bidirectional RNN. So in essence, bidirectional RNNs take up double the resources of either constituent.
Packing it all up
And that’s a wrap on Machine Learning Algorithms Unpacked for 2025! We will continue as always next Sunday, but I just wanted to say a big thanks to YOU for reading. This Substack has been a work in progress for just over a year now, and we’re only just getting started 😎
Here is the usual roundup:
📦 Without full context, RNNs can get confused by homonyms (words with the same spelling but different meaning, like “bank”). This can be detrimental in, say, Named Entity Recognition tasks, where entity ambiguity needs to be minimised.
📦A bidirectional RNN is essentially a pair of RNNs that are run in opposite directions through the data. At each timestep, the hidden state values are combined. Literally, that is- we simply stack the values vertically, then proceed as with a vanilla RNN. This approach allows us to capture context from both previous and future words.
📦 As with any architecture, bidirectional RNNs have their own set of limitations. For example, they cannot be used when future data isn’t available, e.g. for real-time inference or generative applications. Also, they require double the resources of a single RNN structure.
Training complete!
I hope you enjoyed reading as much as I enjoyed writing 😁
Do leave a comment if you’re unsure about anything, if you think I’ve made a mistake somewhere, or if you have a suggestion for what we should learn about next 😎
Until next Sunday,
Ameer
PS… like what you read? If so, feel free to subscribe so that you’re notified about future newsletter releases:
Sources
My GitHub repo where you can find the code for the entire newsletter series: https://github.com/AmeerAliSaleem/machine-learning-algorithms-unpacked
“Bidirectional Recurrent Neural Networks”, by Schuster and Paliwal: https://ieeexplore.ieee.org/document/650093