
Exploring the THREE different types of attention in the 2017 transformer
Masked self-attention, cross-attention, and all the other bells and whistles that contribute to the very first transformer model.

Hello fellow machine learners,
Today, we will (finally) be wrapping up our discussion of the 2017 transformers paper. In particular, the focus will be to understand the following diagram:
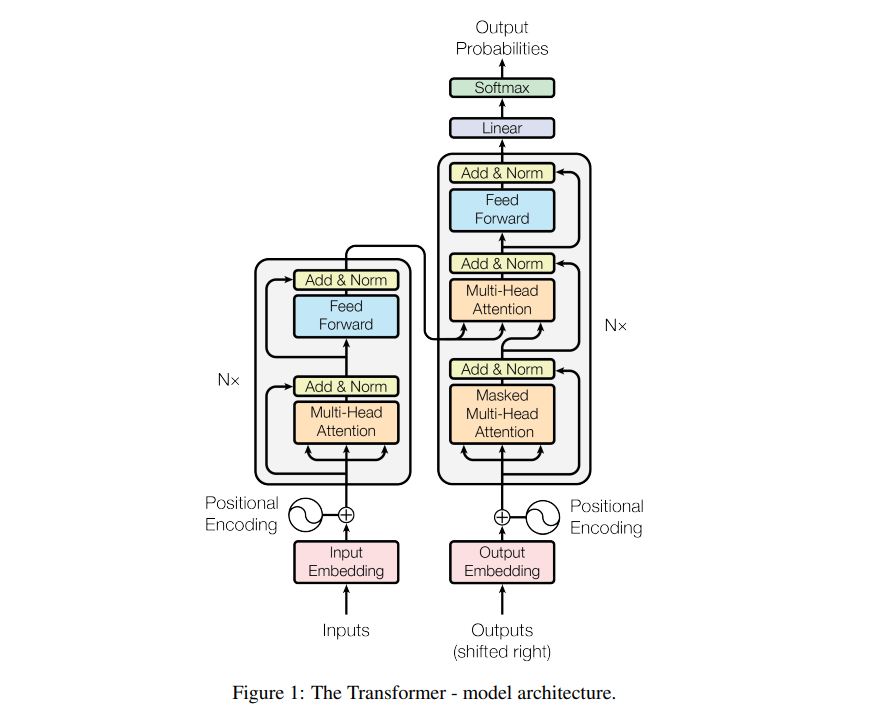
We have spent the past few weeks breaking down the individual components of this diagram. Rather than hitting you with a bunch of article links here, I will draw attention (pun not intended) to any relevant pieces as and when we get to them.
In what follows, I might use “words” and “tokens” interchangeably, as I’ve done before. This interchangeability is not strictly true/correct in reality, but helps simplify the explanations.
Excited? Then let’s get to unpacking!
The encoder
Our example use case will once again be to translate the sentence “you should subscribe to my Substack” to its German equivalent, „du solltest meinen Substack abonnieren”.
We will also have to incorporate tokens to tell the model where the end of each sentence is, which we can represent with the so-called End Of Sentence token <EOS>. For the decoder, we will also need a Beginning Of Sentence token <BOS>, for reasons that will become clear later on.

We provide the full English sentence to the encoder, and the computation for each token is done individually and in parallel as described in the following.
Encoding sub-layer 1: self-attention
We begin by creating word embeddings for each word of our input English sentence. Recall that the paper used an embedding space of 512 dimensions. For each word embedding, we can add a vector of sinusoidal values to create the corresponding positional encoding, which informs the transformer on word order. This is required, because the attention mechanism is designed to learn the contexts of/between words rather than the ordering of the words.
The encoder has two sub-layers, the first of which constitutes the self-attention mechanism. The multi-head attention mechanism described in the paper consists of h=8 independent attention heads that operate in parallel. Thus, each input token gets 8 distinct q, k and v vectors, hence 8 self-attention vectors. All the self-attention vectors for all the words are stitched together in a matrix. According to the paper, two things are done to this matrix before it’s passed to the second sub-layer. I will leave the corresponding papers for you to peruse if you’re interested in the finer details:
💡 Residual connections: the positional encoding values are added to the corresponding self-attention values. In essence, we’re adding the original input for the self-attention mechanism directly to its output. The hope is to prevent the occurrence of the vanishing gradient problem by stabilising gradient flow.
💡 Layer normalisation: the process of standardising the mean and variance of the input to help improve computational efficiency associated with training the network.
Encoding sub-layer 2: feedforward layer
This is the bog-standard neural network layer that we all know and love. In this transformer, the feedforward layer acts on one word embedding at a time.
This sub-layer receives the output from the self-attention sub-layer and fully connects this to an inner layer of 2048 nodes:
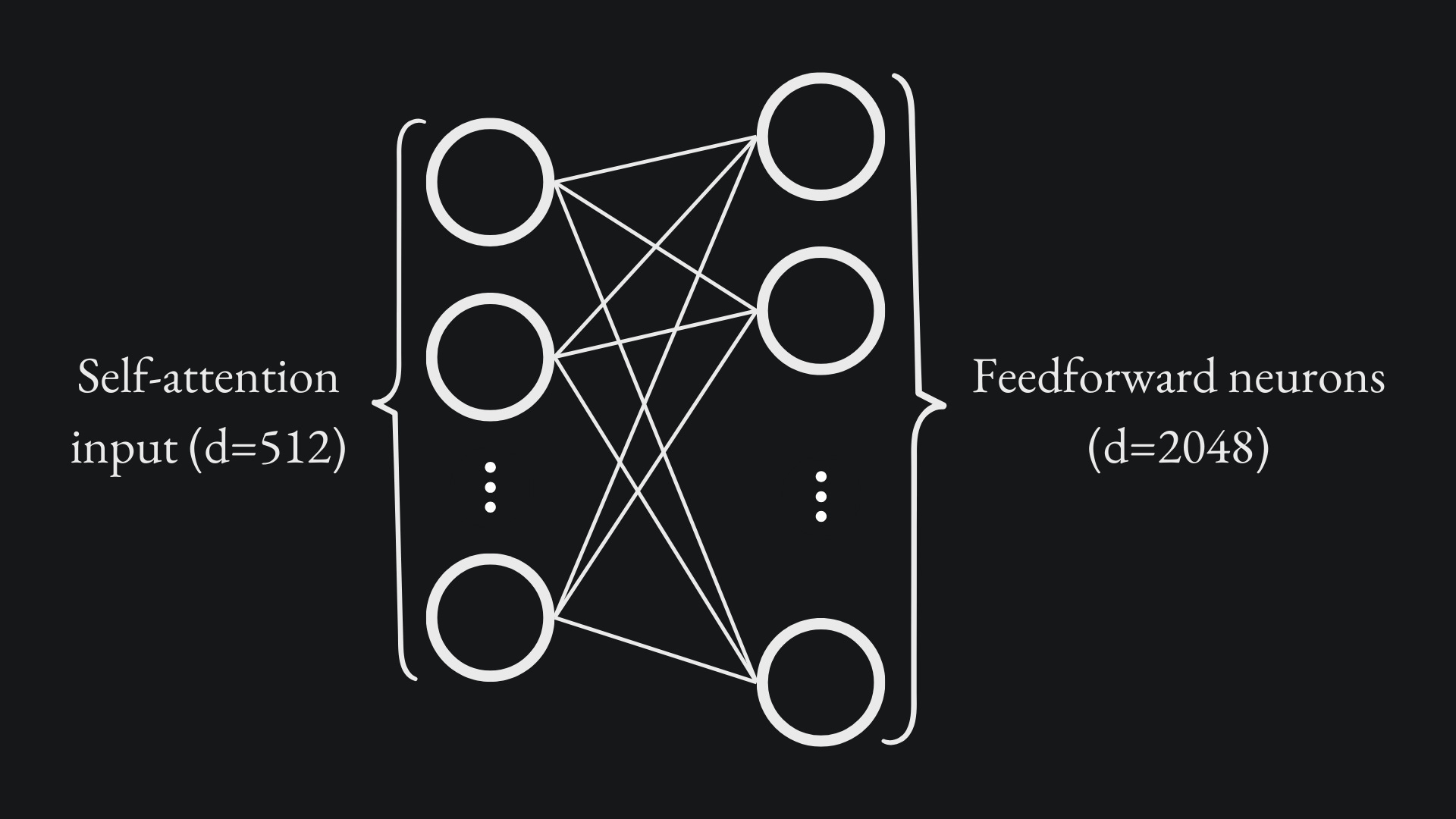
The ReLU activation function is applied at the inner layer. These nodes are then fully connected to an output layer of 512 nodes:
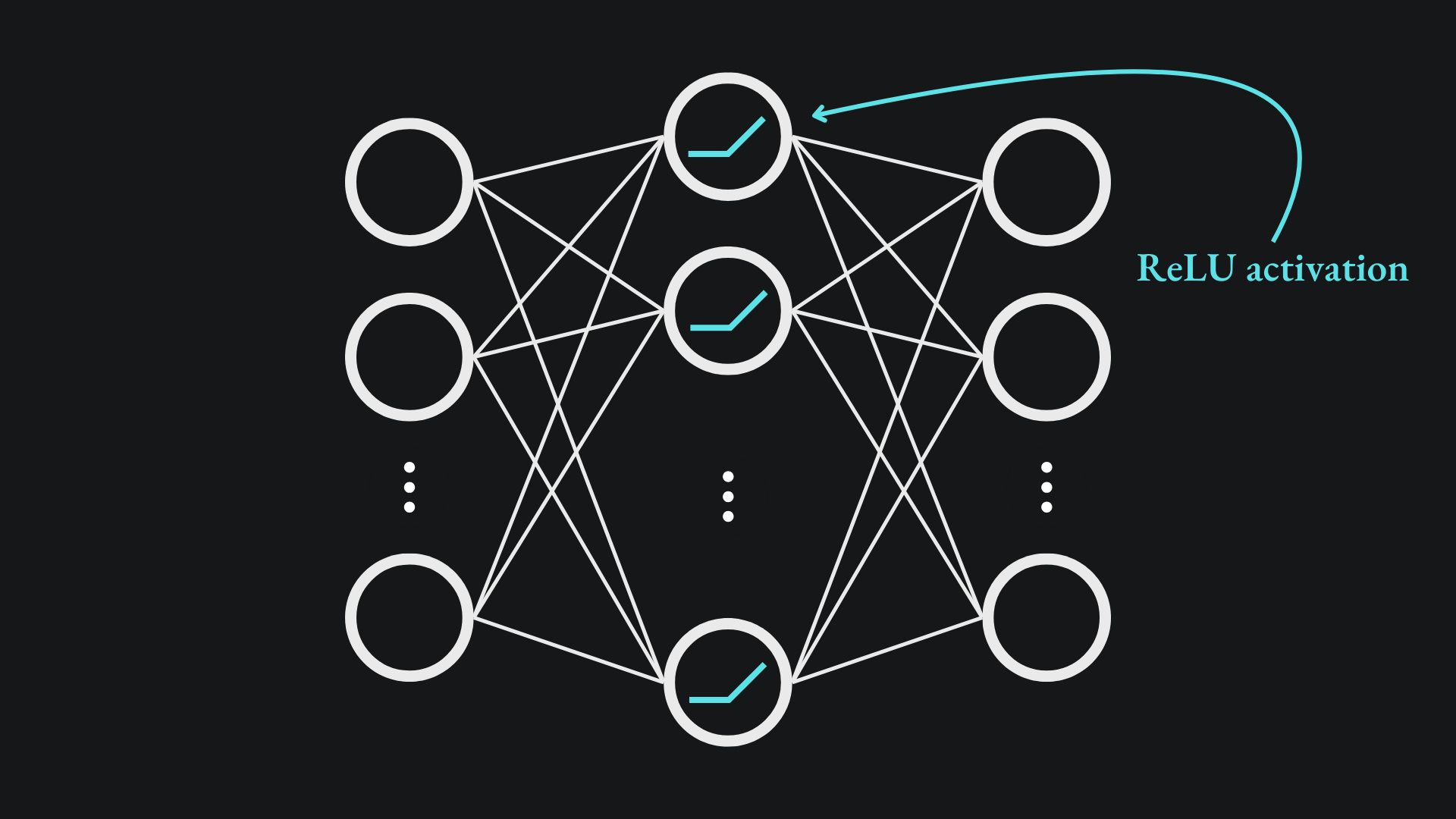
Just like in the previous sub-layer, residual connections and layer normalisation are applied to the output of this sub-layer. It’s worth noting that there is no non-linearity in the feedforward layer. We’re dealing strictly with matrix multiplication + ReLU.
Stack of encoder layers
The reason why the output from the fully connected layer matches the input is because the layers are stacked on top of each other N=6 times. This means that the output from the first pair of sub-layers is passed as input to a second pair of sub-layers, whose output is used as input to third pair, and so on. Here is the diagram, with the omission of the residual connections and layer normalisation procedures:
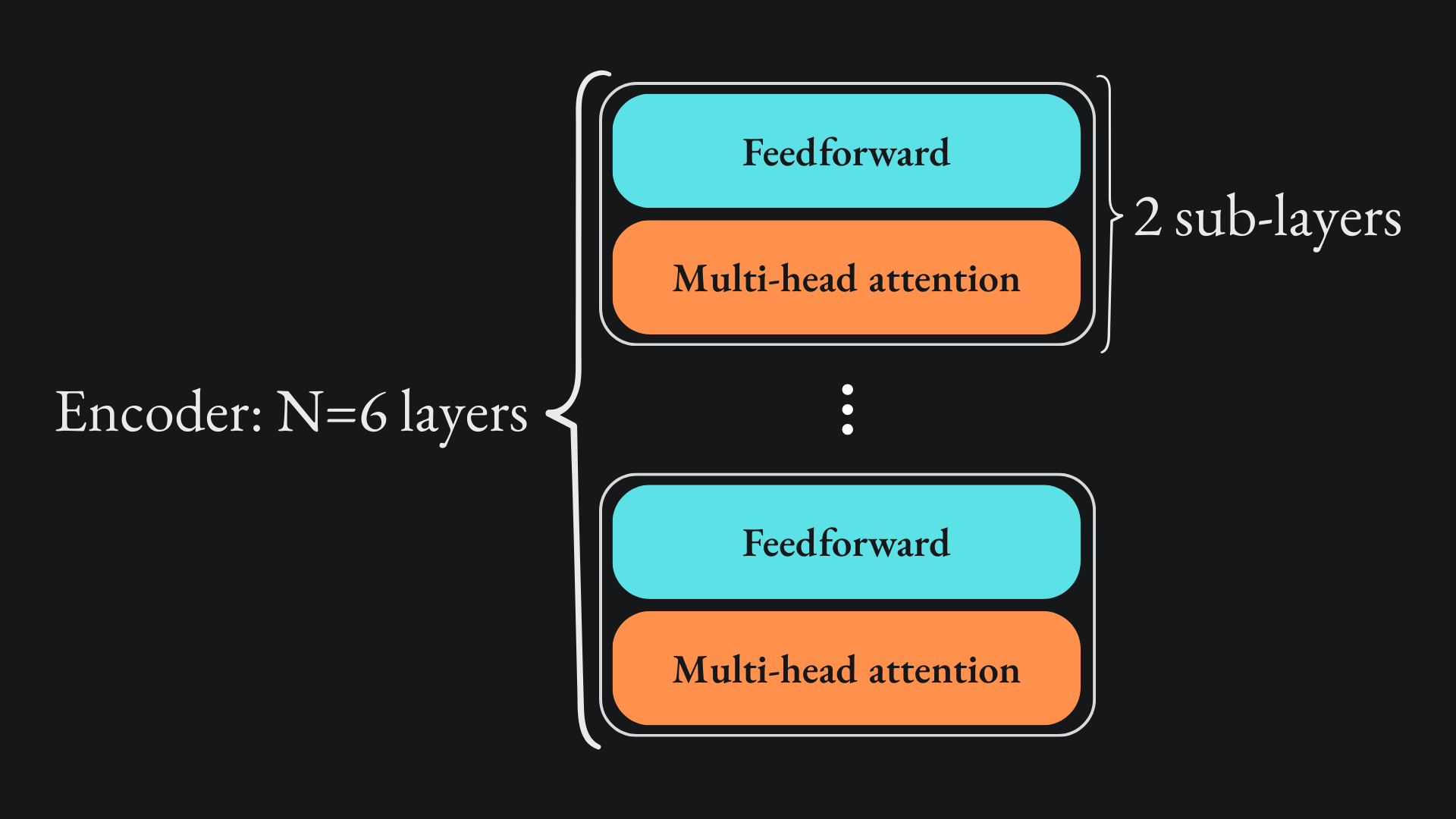
Note that each fully connected sub-layer has its own set of weights and biases. Unlike a recurrent network structure, the parameters are not shared between the sub-layers of separate layers in the stack. For example, the weights and biases of the first feedforward sub-layer are completely separate to those of the feedforward sub-layer of any other layer.
Why repeat the sub-layer pair N times? I’d imagine the researchers experimented with all sorts of sub-layer quantities, values of N, etc. and found this to be the best fit for the encoder. The same sort of experimentation likely went into all other choices of parameters, architectures and so on.
Since the multi-head attention mechanism can be parallelised, we can essentially run all our input tokens through independently at the same time.
Once we’ve finished encoding the entire input text, as signalled with an <EOS> (End Of Sentnece) token, we can move onto…
The decoder
In an encoder-decoder network that’s based on something sequential like a recurrent neural network, we would use the output from the encoder as input for the decoder. We would run each input token through the encoder in order, then use the <EOS> token to signify that the decoder should begin its translation.
Similar to other sequence-to-sequence models, the transformer’s output sequence is produced one token at a time. To that end, we describe the transformer as being auto-regressive; previous words generated in the decoder’s translation are also used by the decoder, alongside the encoder’s output, to inform its translation for future words.
Another thing to note here is that the words in the target language are shifted before being passed to the decoder; once the encoder has completed its task, we start by passing the decoder the <BOS> token, that basically asks the decoder what it thinks the first word in the sentence should be. The decoder has access to the full output from the encoder and works to produce the first word in the translation. With this information, it attempts to figure out the second word in the translation, then uses all this to inform its choice of the third word and so on.
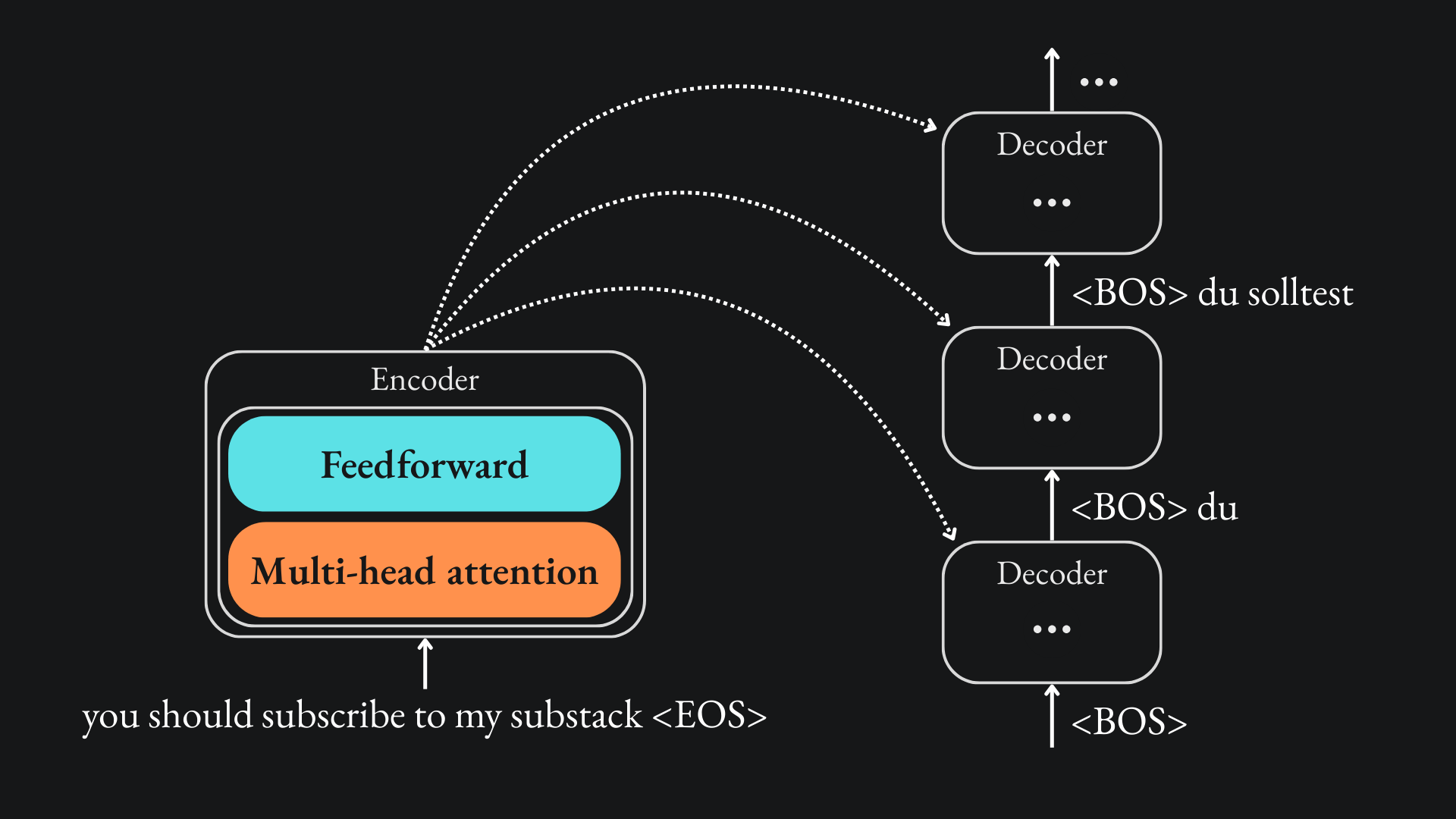
Just like the encoder, the decoder requires a self-attention mechanism to help it understand the context of the tokens in the target language.
But when training the model, we cannot allow earlier words in the translation to attend to words that have yet to appear in the translation. For the example “you should subscribe to my Substack”, the full German translation is available in the training data. However, if the transformer is currently looking to predict the fourth word “Substack” of the translation „du solltest meinen Substack abonnieren”, then we of course shouldn’t reveal the word “Substack” to the model before it has made this prediction! Moreover, we would also not want to tell the model the final word of the sentence “abonnieren”, which could help the model unfairly infer the word “Substack” from the German rather than the information from the encoder (i.e. the original English sentence).
This is entirely different to the encoder, where it was fine for all the words to have the option of attending to any other word. In fact, the encoder needs to the understand the full context of the input sentence, the likes of which can come from anywhere in the given sentence, and so it was in fact necessary to provide the whole sentence for the encoding process.
Quick note before the next section: residual connections and layer normalisation are applied to the output of each sub-layer of the decoder before the values are sent to the next sub-layer, exactly how the encoder’s sub-layers handled it.
Decoder sub-layer 1: masked multi-head attention
Here’s the bottom line: when predicting the ith token in the translation, the decoder should only be able to attend to the (i-1) previous words, not the ith word or onwards.
On the one hand, the decoder’s auto-regressive structure means it must predict new tokens of the translation one at a time. On the other hand, we’ll surely want the decoder to be parallelisable, otherwise the self-attention mechanism loses one of its main edges over previous sequential methods. Is this even possible to satisfy both of these requirements?
It is indeed: the solution is called masked self-attention.
We construct the Query-Key dot product matrix as usual, except we set the values above the leading diagonal to negative infinity:
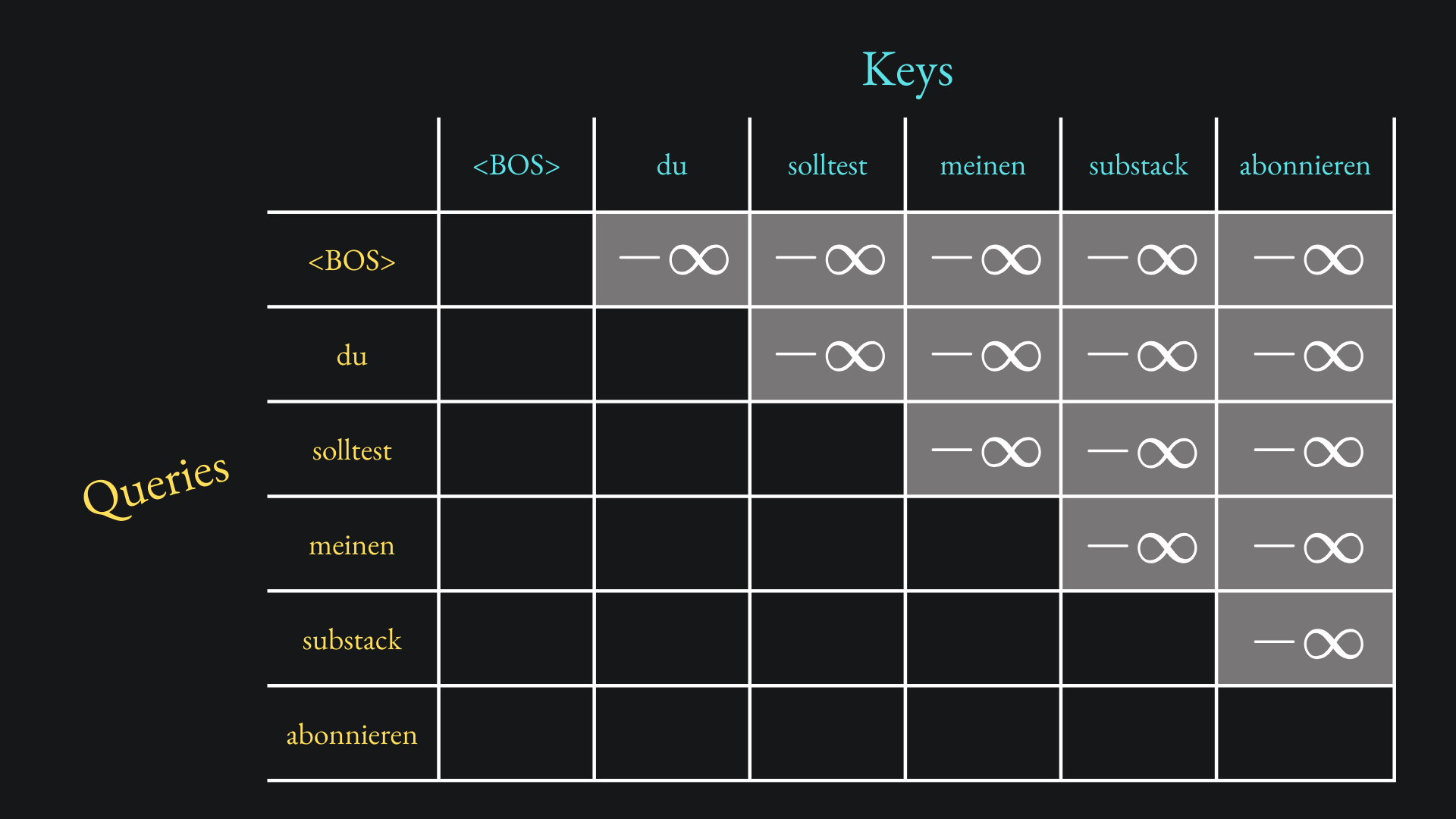
The next step, according to the usual procedure, is to apply the Softmax activation function to each row of this matrix. By doing so, all the negative infinity values will be mapped to 0, as shown by the following limit argument:
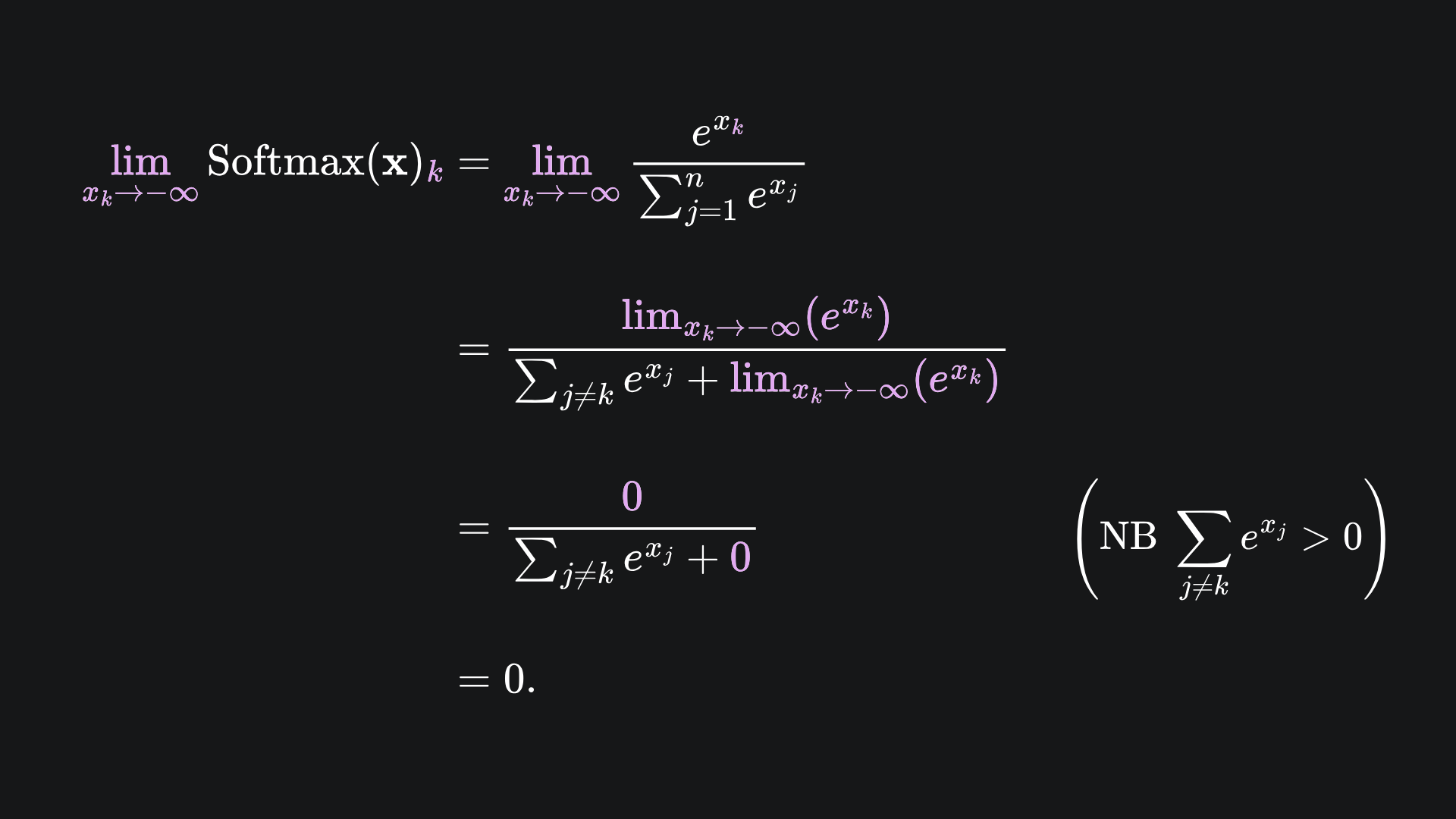
This works to restrict the attention to the ith token and all the preceding tokens.
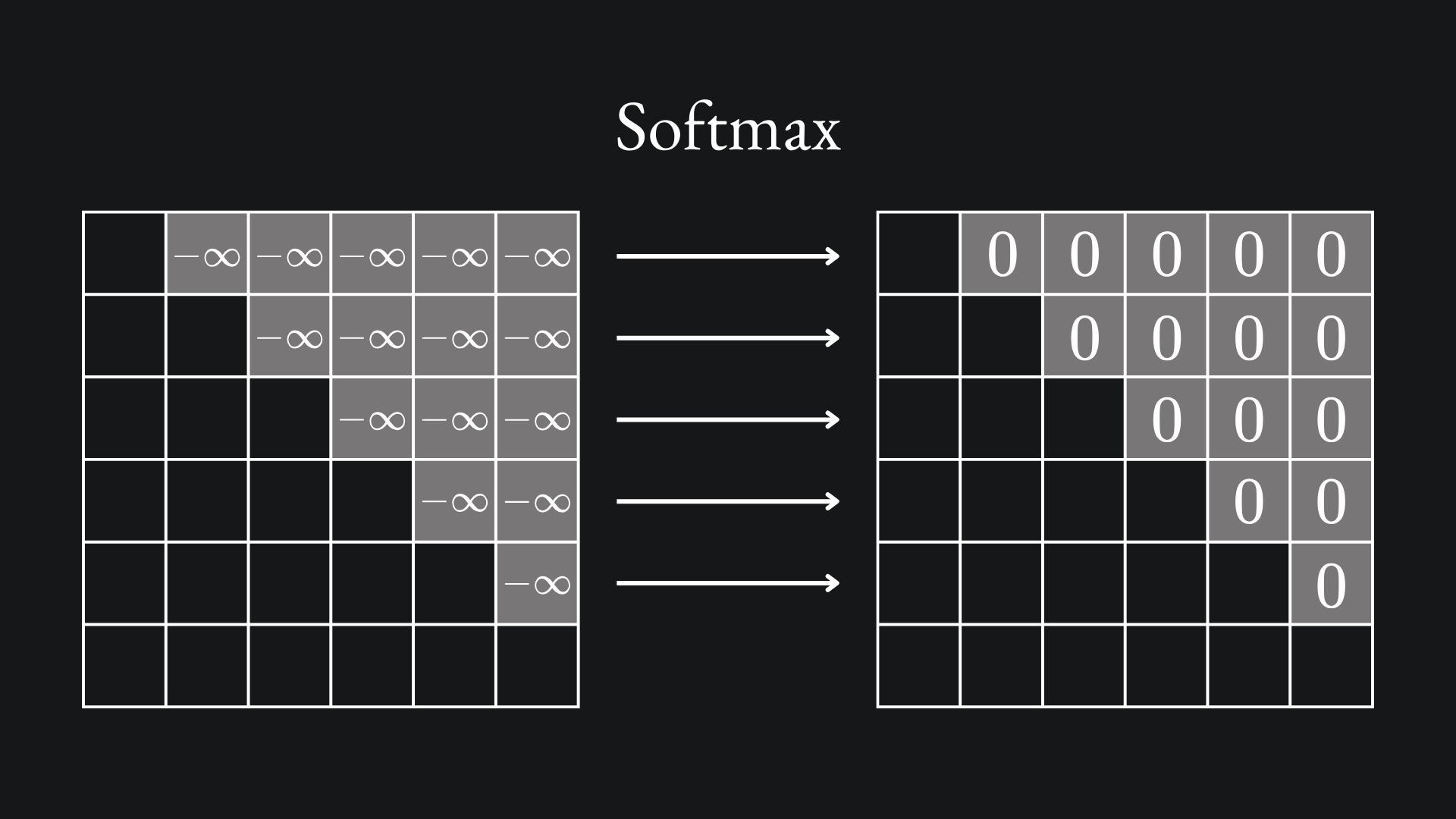
So if we’re looking to make the prediction for the ith token of the translation, then we need only concern ourselves with the ith row of this dot-product matrix, which can only attend to the words that have been generated in the translation up to that point.
For example, if the decoder is at the stage of predicting the word after „meinen” in the translation, then the masked self-attention only allows for attending to the <EOS>, „du”, „solltest” and „meinen” tokens. The decoder will not have access to „Substack” or „abonnieren” yet. However, once we move onto the next word in the translation, we will then have access to „Substack” as well.
With this framework, the parallelisation of the attention mechanism will still work while restricting attention from future segments in the translation. And, similar to the regular version, we can combine multiple heads of this masked mechanism to run in parallel. Nice!
Remember that this mechanism is only meant to help the decoder understand the context between the translated words- we have discussed nothing about the actual translation itself yet. We leave that to…
Decoder sub-layer 2: cross-attention
The decoder is able to attend to tokens in the target language without fear of data leakage. However, the decoder also needs to understand how the target language’s tokens attend to the tokens from our original language. So we will need another separate type of attention between the input and output tokens. We cannot rely on the self-attention mechanism this time, because we’re not interested in the target language tokens attending to themselves. Fortunately, we only need to make a slight tweak to the self-attention mechanism to get what we want.
The standard dot-product matrix contains all the possible combinations of Query-Key dot products. But in this sub-layer of the decoder, the Query vectors come from the German words that have been translated up to that point, while the Key and Value vectors come from the input English sentence.
This is called cross-attention. We want to learn the contextual contributions of the full sentence to the current piece of German we’re at.
For instance, if the decoder has got up to „meinen” in the translation, then the corresponding dot-product matrix will consist of only the q vectors associated with „<BOS> du solltest meinen”, but all the k vectors in English:
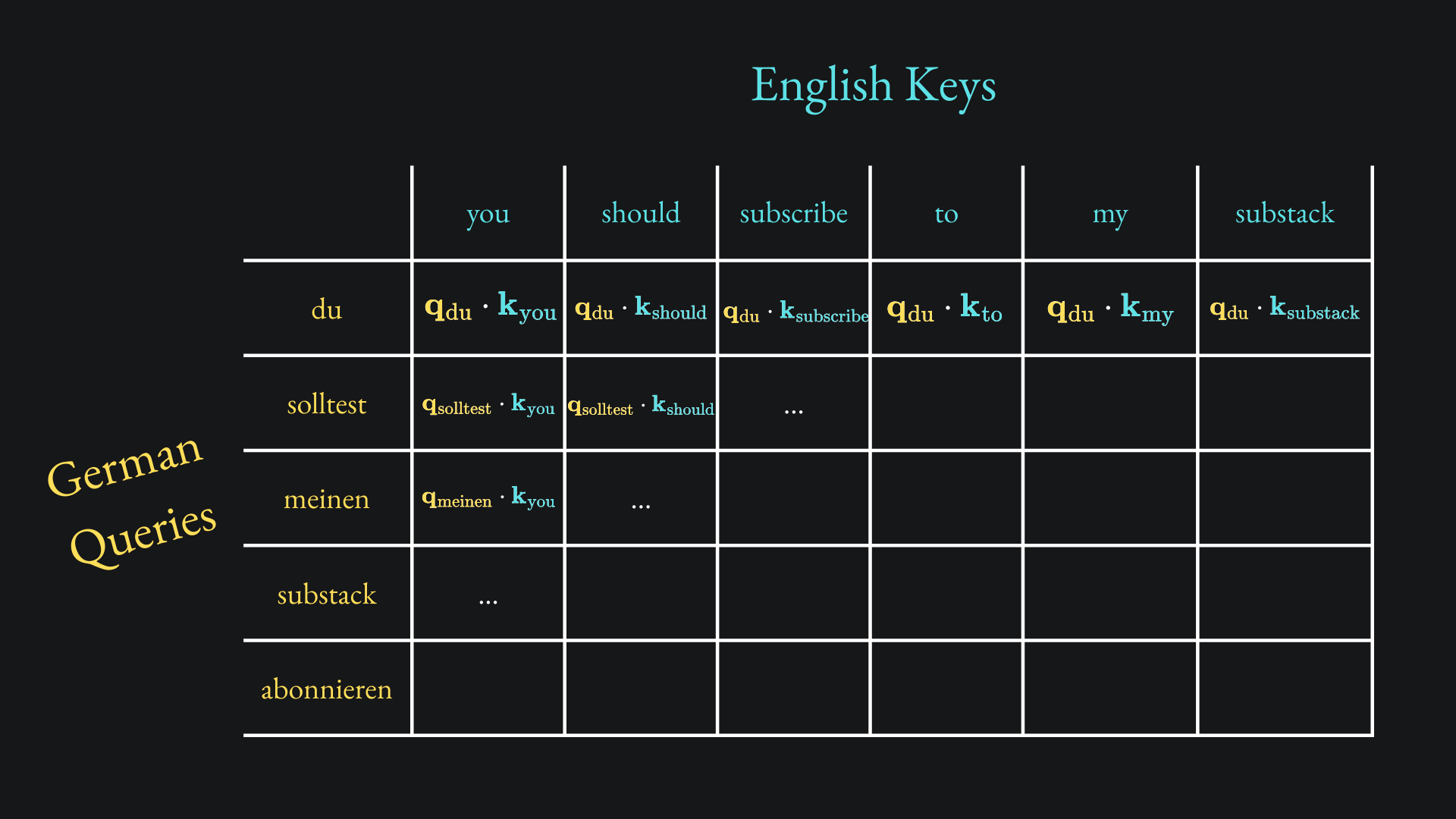
Moreover, the v vectors are associated with the English words. This is because, in the end, the decoder needs to learn how the English self-attention values affect the German words.
Therefore, the main difference between self-attention and cross-attention is that the Queries from the one space attend to the Keys- and consequently affect the influence of the Values- from another space.
Decoder sub-layer 3: feedforward layer
I’ll be honest here: I’m not 100% sure of how the self-attention and cross-attention mechanism outputs are combined. My guess is that they are added together via residual connections as we’ve used before. Please let me know in the comments/DM me if you have more understanding, and I can update this article accordingly.
Either way, the results from the previous two sub-layers are sent to the final sub-layer of the decoder, the feedforward layer. We already discussed this one as part of the encoder architecture, so I won’t repeat it here.
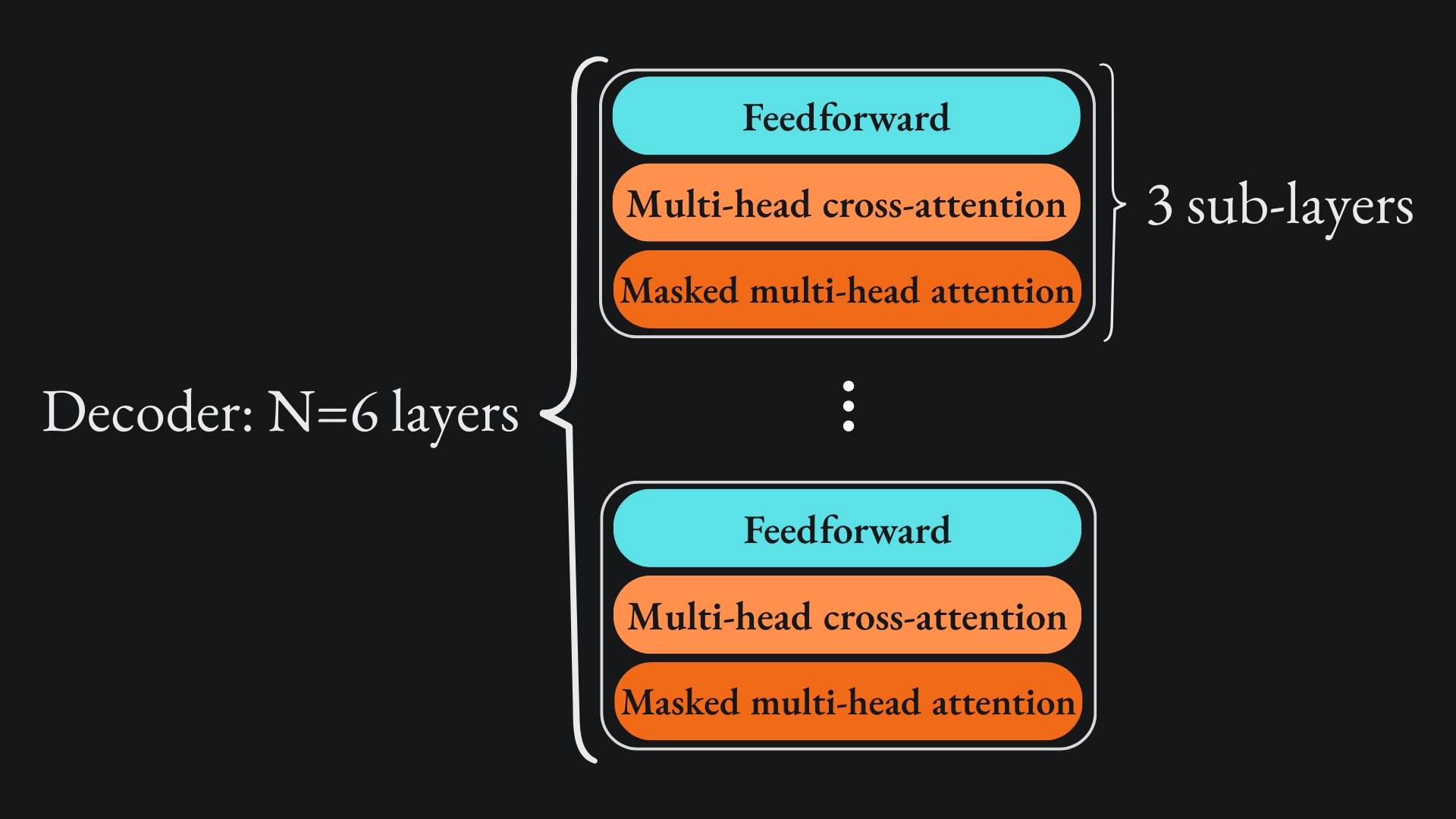
Stack of decoder layers
Similar to the decoder, these three sub-layers are repeated N=6 times. For any individual decoder pass, we:
Compute the masked (multi-head) attention, i.e. self-attention only up to that point in the translation.
Compute the cross-attention to understand how the German words attend to the English words.
Combine everything into a feedforward layer
Rinse and repeat!
Here is the corresponding diagram:
The decoder’s auto-regressive output probabilities
After looping through the N-layer stack, the decoder will be ready to make its next token translation prediction. To do this, we apply a (final) linear transformation to the layer output to transform it into a vector whose dimension matches the size of the German vocabulary, i.e. the number of German words in the training data. We only have five German words in our example „du solltest meinen Substack abonnieren”, but the model would use all German words in reality.
The decoder must now choose which word comes next. To do this, Softmax is applied to the vector, and the next word is determined by the largest Softmax value.
The decoder can be run like this until we get to the end of the translation.
How does the decoder know when to stop decoding?
We’ve remarked on this before, but a great thing about encoder-decoder architectures is that they can work with input and output sequences of varying length. This is great for something like language translation, where we may need multiple German words to represent a single English word, or vice versa. This is a far cry from the capability of a standard neural network, which demands fixed input, output and hidden layer dimensions, as exemplified by the feedforward layers in the encoder and decoder here.
The decoder will be finished with the translation when it outputs an <EOS> token as a prediction. But what if the model never does this? What if it the decoder gets stuck continually spitting out new words, with <EOS> prediction in sight?
Enter teacher forcing. We have all the training data, and so we know that the German translation for “you should subscribe to my Substack” only has five words. Hence, regardless of whether the decoder gets the ith word prediction correct or not, we reveal what the true ith word is in the translation and we force the decoder to use the correct words up to that point for the next predictions.
For instance, if the decoder receives „du solltest” and predicts the next word as „Ohrwurm” (earworm), then we would penalise the model and, rather than allowing it to use „du solltest Ohrwurm” for the next prediction, we would simply tell it to use „du solltest meinen” instead. When we’ve got all the way to „du solltest meinen Substack abonnieren”, if the model does not predict <EOS> for the next (and final) token, then we’d penalise the model and stop the auto-regressive procedure for this training data point.
This prevents the model from deviating in its translation early on, which would have an adverse impact on model learning and training. Additionally, we know exactly where the translation should end and so can order the decoder to stop where it needs to, mitigating similar deviations.
Teacher forcing is a common training technique for sequence-to-sequence models. In fact, it was also used to train the model from the 2014 paper we talked about a few weeks ago (read here!).
Packing it all up
Here is a pretty diagram that summarises the main beats of this article. NB it doesn’t include positional encodings, residual connections, etc.:
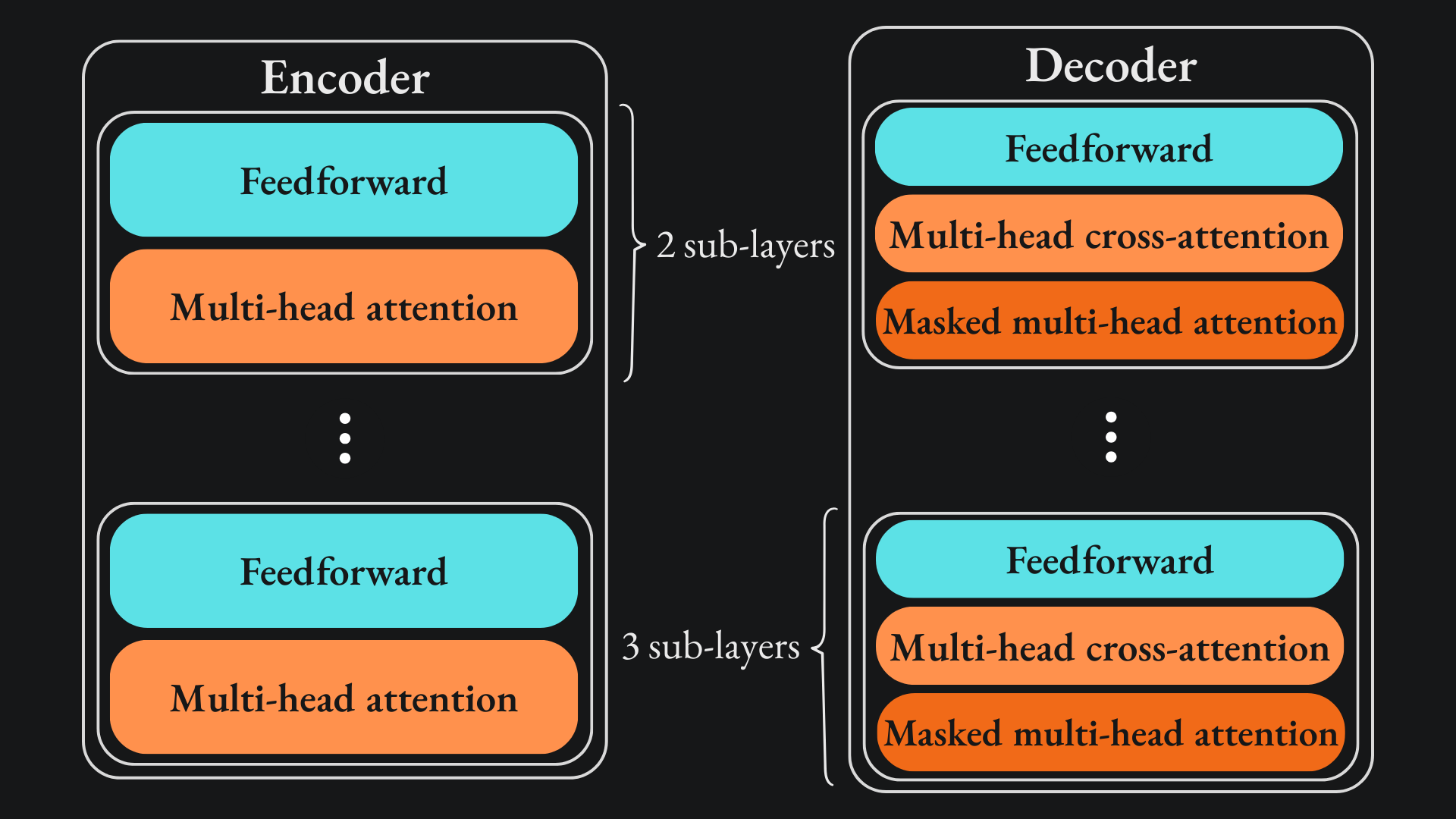
I must admit, I initially found the decoder workflow very confusing to piece together. The structure can be parallelised, yet information can only be spoon-fed to the decoder due to the auto-regressive aspect of the model. Hopefully, I have done justice to explaining the decoder’s components well, let me know in the comments if not.
There is still so much more we could discuss on this topic (e.g. model performance metrics). That said, I would prefer to keep this Substack focussed on the theoretical aspects of machine learning, because that’s the part that I think requires/deserves further explanation. Let me know your thoughts on this approach in the comments.
A quick roundup as always:
📦 The encoder is comprised of N=6 layers, each containing two sub-layers. The decoder is similar, but has a third sub-layer before the other two. The transformer can ingest the full source training sample all at once. However, the transformer’s output sequence is produced one token at a time. To that end, we describe the transformer as being auto-regressive; previous words generated in the decoder’s translation are also used by the decoder, alongside the encoder’s output, to inform its translation for future words.
📦 “Teacher forcing” can be used to prevent the transformer from entering an endless token prediction loop. Regardless of whether the decoder gets the i-th word prediction correct or not, we reveal to it what the true i-th word is in the translation and we force the decoder to use the correct words up to that point for the future predictions.
📦 The 2017 transformer leverages THREE different types of attention mechanism between the encoder and decoder: self-attention (encoder), masked self-attention (decoder) and cross-attention (encoder-decoder). Each type can, of course, be parallelised in the form of a multi-head attention mechanism.
Training complete!
I hope you enjoyed reading as much as I enjoyed writing 😁
Do leave a comment if you’re unsure about anything, if you think I’ve made a mistake somewhere, or if you have a suggestion for what we should learn about next 😎
Until next Sunday,
Ameer
PS… like what you read? If so, feel free to subscribe so that you’re notified about future newsletter releases: